
-
1. 起步
-
2. Git 基础
-
3. Git 分支
-
4. 服务器上的 Git
- 4.1 协议
- 4.2 在服务器上部署 Git
- 4.3 生成 SSH 公钥
- 4.4 架设服务器
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 第三方托管服务
- 4.10 小结
-
5. 分布式 Git
-
A1. 附录 A: Git 在其他环境
- A1.1 图形界面
- A1.2 Visual Studio 中的 Git
- A1.3 Visual Studio Code 中的 Git
- A1.4 IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine 中的 Git
- A1.5 Sublime Text 中的 Git
- A1.6 Bash 中的 Git
- A1.7 Zsh 中的 Git
- A1.8 PowerShell 中的 Git
- A1.9 小结
-
A2. 附录 B: 在应用程序中嵌入 Git
-
A3. 附录 C: Git 命令
10.2 Git 内部原理 - Git 对象
Git 对象
Git 是一个内容寻址的文件系统。很好。这意味着什么?这意味着 Git 的核心是一个简单的键值数据存储。这意味着你可以将任何类型的内容放入 Git 仓库,Git 会为你提供一个唯一的密钥,你以后可以使用该密钥来检索该内容。
作为演示,我们来看一下 `git hash-object` 这个底层命令,它接受一些数据,将其存储在你的 `.git/objects` 目录(即对象数据库)中,并返回一个唯一标识该数据对象的密钥。
首先,你初始化一个新的 Git 仓库,并验证 `objects` 目录中(正如预期的那样)是空的
$ git init test
Initialized empty Git repository in /tmp/test/.git/
$ cd test
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type fGit 已初始化 `objects` 目录,并在其中创建了 `pack` 和 `info` 子目录,但没有常规文件。现在,让我们使用 `git hash-object` 创建一个新的数据对象并手动将其存储在你的新 Git 数据库中
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4在最简单的形式下,`git hash-object` 将你提供给它的内容,仅仅返回一个将会用于将其存储在你的 Git 数据库中的唯一密钥。`-w` 选项然后告诉命令不要仅仅返回密钥,而是将该对象写入数据库。最后,`--stdin` 选项告诉 `git hash-object` 从标准输入获取要处理的内容;否则,命令将在命令末尾期望一个包含要使用内容的文件名参数。
上述命令的输出是一个 40 个字符的校验和哈希。这是 SHA-1 哈希——你正在存储的内容加上一个头部信息的校验和,稍后你将了解到这一点。现在你可以看到 Git 是如何存储你的数据的
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4如果你再次检查你的 `objects` 目录,你会看到它现在包含了一个代表新内容的文件。这就是 Git 最初存储内容的方式——每个内容都作为一个单独的文件,以内容及其头部信息的 SHA-1 校验和命名。子目录用 SHA-1 的前 2 个字符命名,文件名是剩余的 38 个字符。
一旦你的对象数据库中有内容,你就可以使用 `git cat-file` 命令检查该内容。这个命令就像一个瑞士军刀,用于检查 Git 对象。将 `-p` 传递给 `cat-file` 会指示命令首先确定内容类型,然后适当地显示它
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content现在,你可以将内容添加到 Git 并将其取回。你也可以通过文件中的内容来完成此操作。例如,你可以对一个文件进行简单的版本控制。首先,创建一个新文件并将其内容保存到你的数据库中
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30然后,向文件中写入一些新内容,并再次保存
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a你的对象数据库现在包含这个新文件的两个版本(以及你最初存储在那里的内容)
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4此时,你可以删除 `test.txt` 文件的本地副本,然后使用 Git 从对象数据库中检索第一个版本
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1或第二个版本
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2但是记住每个文件版本的 SHA-1 密钥并不实用;而且,你并没有在你的系统中存储文件名——只有内容。这种对象类型称为blob。给定任何对象的 SHA-1 密钥,你可以让 Git 告诉你是哪种对象类型,使用 `git cat-file -t`
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blob树对象
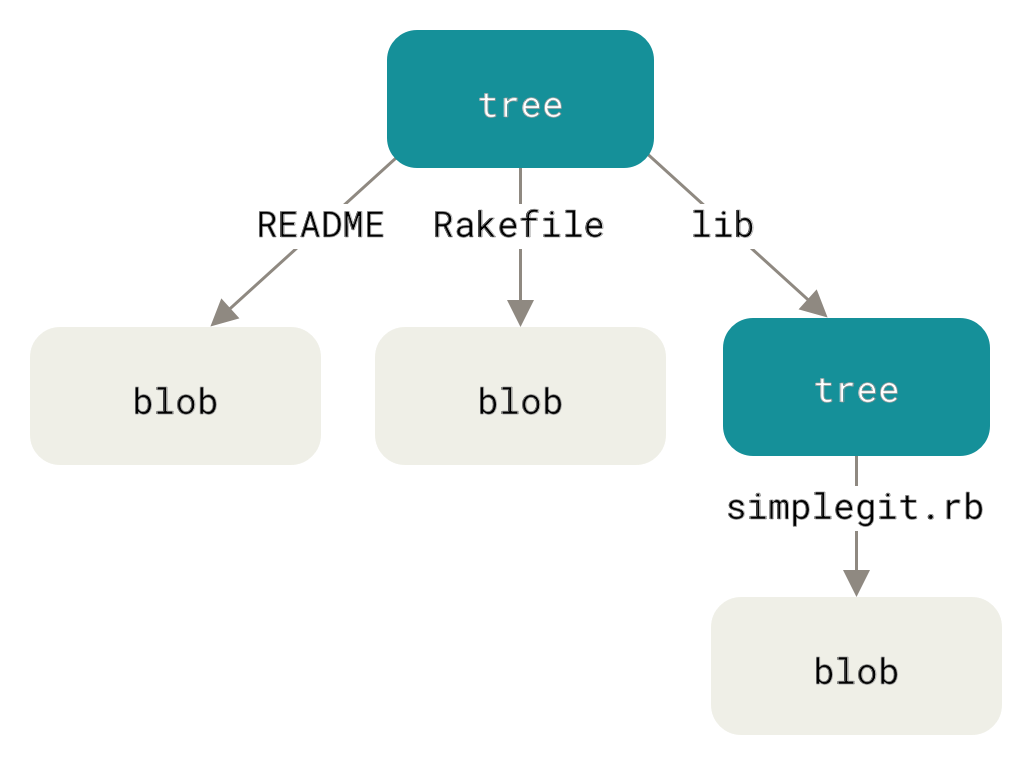
我们要检查的下一类 Git 对象是树,它解决了存储文件名的问题,并且还允许你将一组文件一起存储。Git 以一种类似于 UNIX 文件系统的方式存储内容,但稍微简化了一些。所有内容都存储为树和 blob 对象,其中树对象对应于 UNIX 目录条目,blob 对象大致对应于 inode 或文件内容。一个单独的树对象包含一个或多个条目,每个条目都是一个 blob 或子树的 SHA-1 哈希,以及相关的模式、类型和文件名。例如,假设你有一个项目,其中最新的树看起来像这样
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 lib`master^{tree}` 语法指定了你的 `master` 分支上最后一个提交所指向的树对象。注意 `lib` 子目录不是一个 blob,而是指向另一个树的指针
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb|
注意
|
根据你使用的 shell,在使用 `master^{tree}` 语法时可能会遇到错误。 在 Windows 的 CMD 中,`^` 字符用于转义,所以你必须将它加倍才能避免这个问题:`git cat-file -p master^^{tree}`。在使用 PowerShell 时,使用 `{}` 字符的参数必须被引用,以避免参数被错误解析:`git cat-file -p 'master^{tree}'`。 如果你正在使用 ZSH,`^` 字符用于 globbing,所以你必须将整个表达式用引号括起来:`git cat-file -p "master^{tree}"`。 |
概念上,Git 正在存储的数据看起来像这样
你可以很容易地创建自己的树。Git 通常通过获取暂存区或索引的状态来创建一个树,并从中写入一系列树对象。所以,要创建一个树对象,你首先必须通过暂存一些文件来设置索引。要创建一个包含单个条目的索引——你的 `test.txt` 文件的第一个版本——你可以使用底层命令 `git update-index`。你使用这个命令来人为地将 `test.txt` 文件的早期版本添加到新的暂存区。你必须传递 `--add` 选项,因为文件还没有出现在你的暂存区中(你甚至还没有设置暂存区),以及 `--cacheinfo`,因为你要添加的文件不在你的目录中,而是在你的数据库中。然后,你指定模式、SHA-1 和文件名
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txt在这种情况下,你指定模式为 `100644`,这意味着它是一个普通文件。其他选项是 `100755`,表示它是可执行文件;`120000` 表示符号链接。模式取自常规的 UNIX 模式,但灵活性要小得多——这三种模式是 Git 中文件(blob)唯一有效的模式(尽管目录和子模块使用其他模式)。
现在,你可以使用 `git write-tree` 将暂存区写入树对象。不需要 `-w` 选项——调用此命令会在该树尚不存在的情况下自动从索引的状态创建一个树对象
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt你还可以使用前面看到的相同的 `git cat-file` 命令来验证这是一个树对象
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree你现在将创建一个包含 `test.txt` 第二个版本和一个新文件的新树
$ echo 'new file' > new.txt
$ git update-index --cacheinfo 100644 \
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
$ git update-index --add new.txt你的暂存区现在包含 `test.txt` 的新版本以及新文件 `new.txt`。写入该树(将暂存区或索引的状态记录到树对象)并查看它的样子
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
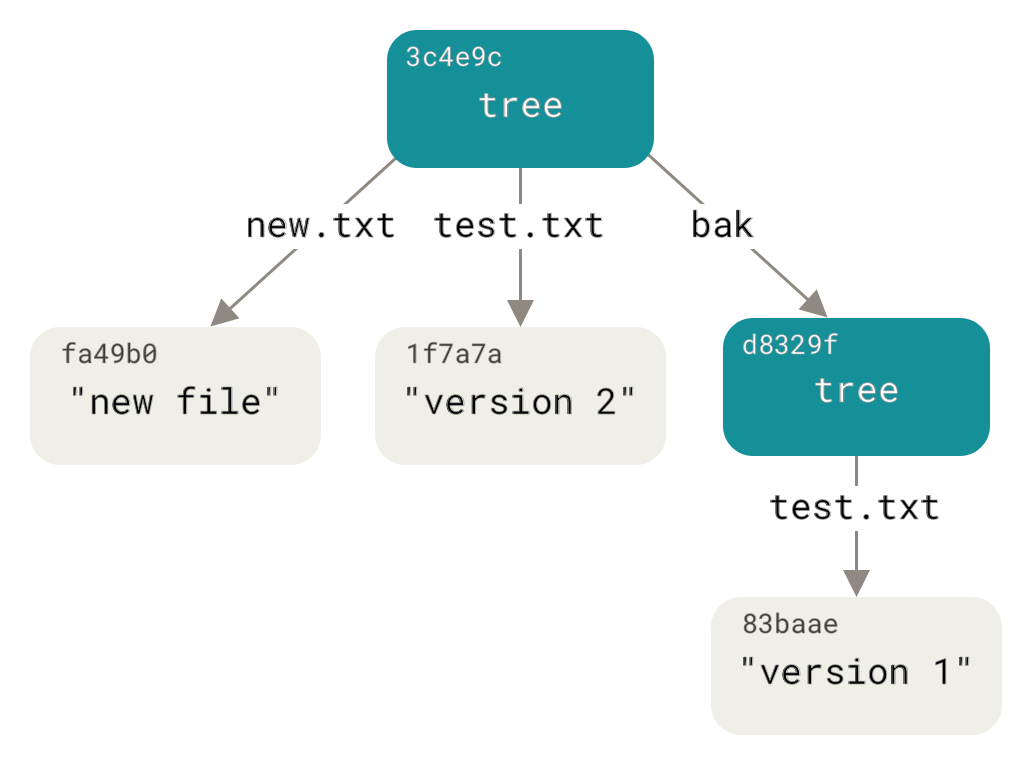
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt请注意,此树同时包含两个文件条目,并且 `test.txt` 的 SHA-1 是早期“版本 2”的 SHA-1(`1f7a7a`)。仅为好玩,你将第一个树添加为其中一个子目录。你可以通过调用 `git read-tree` 将树读入你的暂存区。在这种情况下,你可以使用此命令的 `--prefix` 选项将现有树作为子树读入你的暂存区
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt如果你从刚才写入的新树创建了一个工作目录,你将在工作目录的顶层看到两个文件,以及一个名为 `bak` 的子目录,其中包含 `test.txt` 文件的第一个版本。你可以将 Git 中包含的这些结构的数据视为如下所示
提交对象
如果你已经完成了以上所有操作,那么你现在已经有了三个代表你想要跟踪的项目快照的树,但之前的问题仍然存在:你必须记住所有三个 SHA-1 值才能回忆起这些快照。你也没有关于谁保存了这些快照、何时保存、为什么保存的信息。这就是提交对象为你存储的基本信息。
要创建一个提交对象,你需要调用 `commit-tree` 并指定一个树的 SHA-1 以及它直接前驱的提交对象(如果有)。从你写入的第一个树开始
$ echo 'First commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d|
注意
|
由于创建时间和作者数据不同,你会得到一个不同的哈希值。此外,虽然理论上任何提交对象都可以通过这些数据精确地重现,但本书构建的历史细节意味着打印出的提交哈希可能与给定提交不符。在本章的后续内容中,请将提交和标签哈希替换为你自己的校验和。 |
现在你可以使用 `git cat-file` 查看你的新提交对象了
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
First commit提交对象格式很简单:它指定了该时间点项目快照的顶级树;父提交(如果有)(上面描述的提交对象没有父提交);作者/提交者信息(使用你的 `user.name` 和 `user.email` 配置设置以及时间戳);一个空行,然后是提交消息。
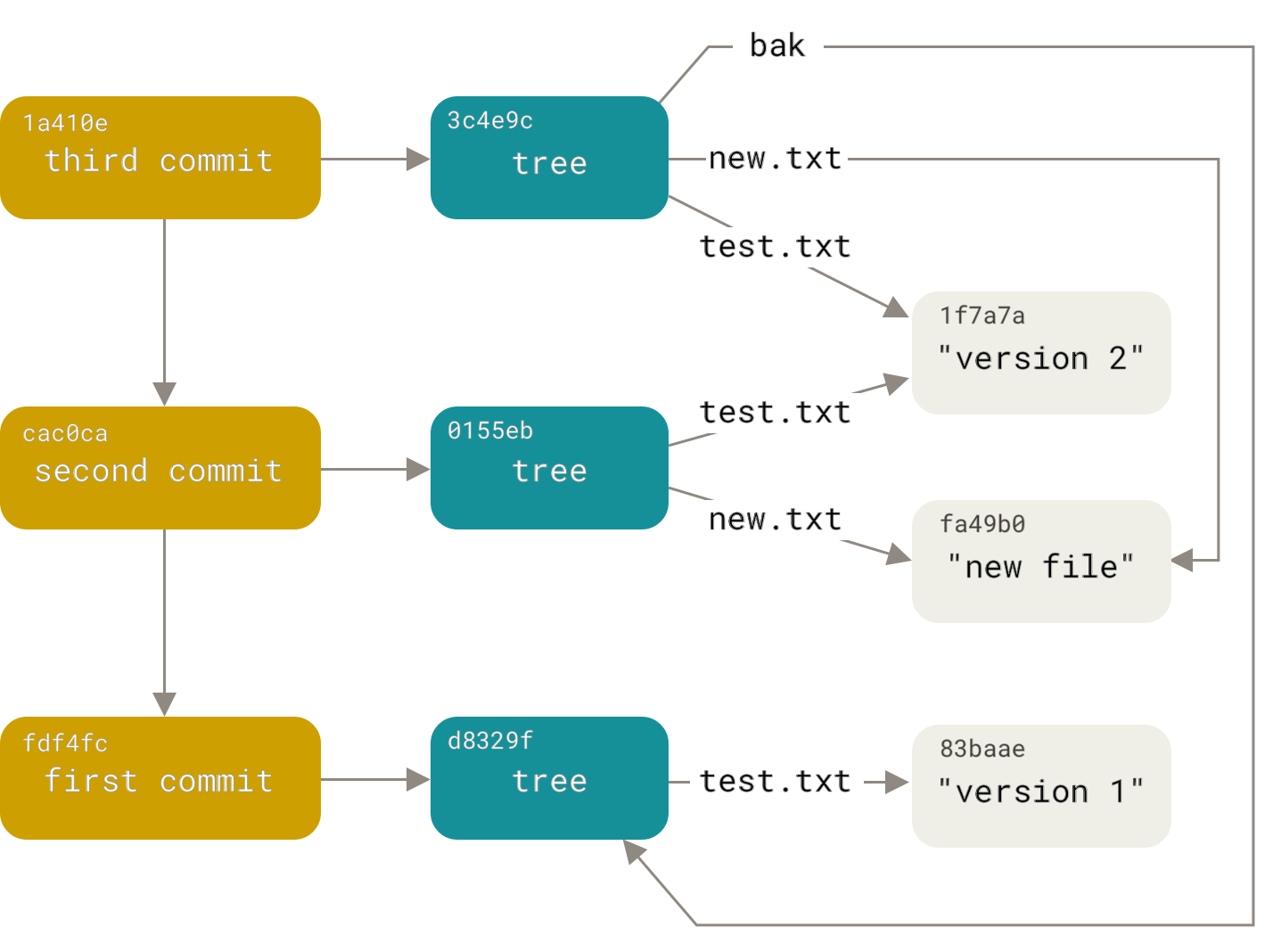
接下来,你将编写另外两个提交对象,每个对象都引用直接在其之前的提交
$ echo 'Second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'Third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9这三个提交对象中的每一个都指向你创建的三个快照树之一。令人惊讶的是,你现在拥有一个真实的 Git 历史,如果你在最后一个提交 SHA-1 上运行 `git log` 命令,就可以查看它
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
Third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
Second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
First commit
test.txt | 1 +
1 file changed, 1 insertion(+)太棒了。你刚刚完成了构建 Git 历史的底层操作,而没有使用任何前端命令。这基本上就是你运行 `git add` 和 `git commit` 命令时 Git 所做的——它为已更改的文件存储 blob,更新索引,写入树,并写入引用顶级树和它们的前一个提交的提交对象。这三个主要的 Git 对象——blob、tree 和 commit——最初存储在你的 `.git/objects` 目录中的单独文件中。这里是示例目录中所有对象的列表,并注释了它们存储的内容
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1如果你遵循所有内部指针,你会得到一个类似这样的对象图
对象存储
我们之前提到,你提交到 Git 对象数据库的每个对象都存储着一个头部信息。花点时间看看 Git 是如何存储对象的。你将看到如何在 Ruby 脚本语言中交互式地存储一个 blob 对象——在这种情况下,字符串是“what is up, doc?”。
你可以使用 `irb` 命令启动交互式 Ruby 模式
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"Git 首先构建一个头部信息,该头部信息以标识对象类型开始——在这种情况下是 blob。对于头部的第一部分,Git 添加一个空格,然后是内容的字节大小,最后添加一个空字节
>> header = "blob #{content.bytesize}\0"
=> "blob 16\u0000"Git 将头部和原始内容连接起来,然后计算新内容的 SHA-1 校验和。你可以通过包含 SHA1 digest 库并使用 `require` 命令,然后使用字符串调用 `Digest::SHA1.hexdigest()` 来计算 Ruby 中字符串的 SHA-1 值
>> store = header + content
=> "blob 16\u0000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"让我们将其与 `git hash-object` 的输出进行比较。这里我们使用 `echo -n` 来防止在输入中添加换行符。
$ echo -n "what is up, doc?" | git hash-object --stdin
bd9dbf5aae1a3862dd1526723246b20206e5fc37Git 使用 zlib 压缩新内容,你可以在 Ruby 中使用 zlib 库来完成。首先,你需要 `require` 该库,然后对内容运行 `Zlib::Deflate.deflate()`
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\x9CK\xCA\xC9OR04c(\xCFH,Q\xC8,V(-\xD0QH\xC9O\xB6\a\x00_\x1C\a\x9D"最后,你将把 zlib 压缩后的内容写入磁盘上的一个对象。你将确定要写入的对象路径(SHA-1 值的前两个字符作为子目录名称,后 38 个字符作为目录内的文件名)。在 Ruby 中,你可以使用 `FileUtils.mkdir_p()` 函数在子目录不存在时创建它。然后,使用 `File.open()` 打开文件,并使用 `write()` 调用将之前 zlib 压缩的内容写入文件句柄
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32让我们使用 `git cat-file` 检查对象的内容
---
$ git cat-file -p bd9dbf5aae1a3862dd1526723246b20206e5fc37
what is up, doc?
---就这样——你已经创建了一个有效的 Git blob 对象。
所有 Git 对象都以相同的方式存储,只是类型不同——头部不是以字符串 blob 开始,而是以 commit 或 tree 开始。另外,虽然 blob 的内容几乎可以是任何东西,但 commit 和 tree 的内容格式非常特定。