
-
1. 起步
-
2. Git 基础
-
3. Git 分支
-
4. 服务器上的 Git
- 4.1 协议
- 4.2 在服务器上部署 Git
- 4.3 生成 SSH 公钥
- 4.4 架设服务器
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 第三方托管服务
- 4.10 小结
-
5. 分布式 Git
-
A1. 附录 A: Git 在其他环境
- A1.1 图形界面
- A1.2 Visual Studio 中的 Git
- A1.3 Visual Studio Code 中的 Git
- A1.4 IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine 中的 Git
- A1.5 Sublime Text 中的 Git
- A1.6 Bash 中的 Git
- A1.7 Zsh 中的 Git
- A1.8 PowerShell 中的 Git
- A1.9 小结
-
A2. 附录 B: 在应用程序中嵌入 Git
-
A3. 附录 C: Git 命令
7.7 Git 工具 - Reset 详解
Reset 详解
在深入更专业的工具之前,我们先来讨论 Git 的 reset 和 checkout 命令。这应该是 Git 中最容易让人感到困惑的部分。它们能做的事情太多了,以至于我们似乎很难真正理解并恰当地使用它们。为了帮助你理解,我们推荐一个简单的比喻。
三棵树
理解 reset 和 checkout 的一个更简单的方法是,将 Git 想象成一个管理三种不同“树”(文件集合)的内容管理器。在这里,“树”指的是“文件集合”,而不是特指数据结构。在某些情况下,索引(index)的行为并不完全像一棵树,但为了方便理解,我们暂时可以这样想。
Git 系统在正常操作中管理和操作着三棵树
| 树 | 角色 |
|---|---|
HEAD |
上一次提交的快照,下一个父提交 |
索引 (Index) |
将要提交的下一个快照 |
工作目录 (Working Directory) |
沙盒 |
HEAD
HEAD 是指向当前分支引用的指针,而分支引用又指向该分支上的最后一次提交。这意味着 HEAD 将是下一次创建的提交的父提交。通常最简单的理解方式是,HEAD 是**你在此分支上最后一次提交的快照**。
实际上,要查看这个快照的样子非常容易。下面是一个示例,展示了如何获取 HEAD 快照中每个文件的实际目录列表和 SHA-1 校验和。
$ git cat-file -p HEAD
tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf
author Scott Chacon 1301511835 -0700
committer Scott Chacon 1301511835 -0700
initial commit
$ git ls-tree -r HEAD
100644 blob a906cb2a4a904a152... README
100644 blob 8f94139338f9404f2... Rakefile
040000 tree 99f1a6d12cb4b6f19... libGit 的 cat-file 和 ls-tree 命令是“管道”命令,用于较低级别的操作,在日常工作中并不常用,但它们有助于我们理解这里发生的事情。
索引 (Index)
索引是你**打算提交的下一个快照**。我们之前也把它称为 Git 的“暂存区”,因为当你运行 git commit 时,Git 查看的就是这里的内容。
Git 会用一份列表来填充这个索引,列表包含所有你上次检出到工作目录的文件内容及其原始状态。然后,你可以替换其中的一些文件,用它们的新版本。git commit 会将这些内容转换为一个新提交的树。
$ git ls-files -s
100644 a906cb2a4a904a152e80877d4088654daad0c859 0 README
100644 8f94139338f9404f26296befa88755fc2598c289 0 Rakefile
100644 47c6340d6459e05787f644c2447d2595f5d3a54b 0 lib/simplegit.rb同样,这里我们使用了 git ls-files,这是一个更偏向幕后的命令,它展示了你当前索引的样子。
技术上来说,索引并不是一个树结构——它实际上被实现为一个扁平的清单(manifest)——但对我们目前的理解来说,已经足够接近了。
工作目录 (Working Directory)
最后,你拥有你的工作目录(也常被称为“工作树”)。另外两棵树将它们的内容以一种高效但不方便的方式存储在 .git 文件夹内。工作目录将它们解压成实际的文件,方便你进行编辑。将工作目录看作一个**沙盒**,你可以在提交到暂存区(索引)然后提交到历史记录之前,在这里尝试修改。
$ tree
.
├── README
├── Rakefile
└── lib
└── simplegit.rb
1 directory, 3 files工作流程
Git 的典型工作流程是通过操作这三棵树,以逐步改进的状态记录项目的快照。
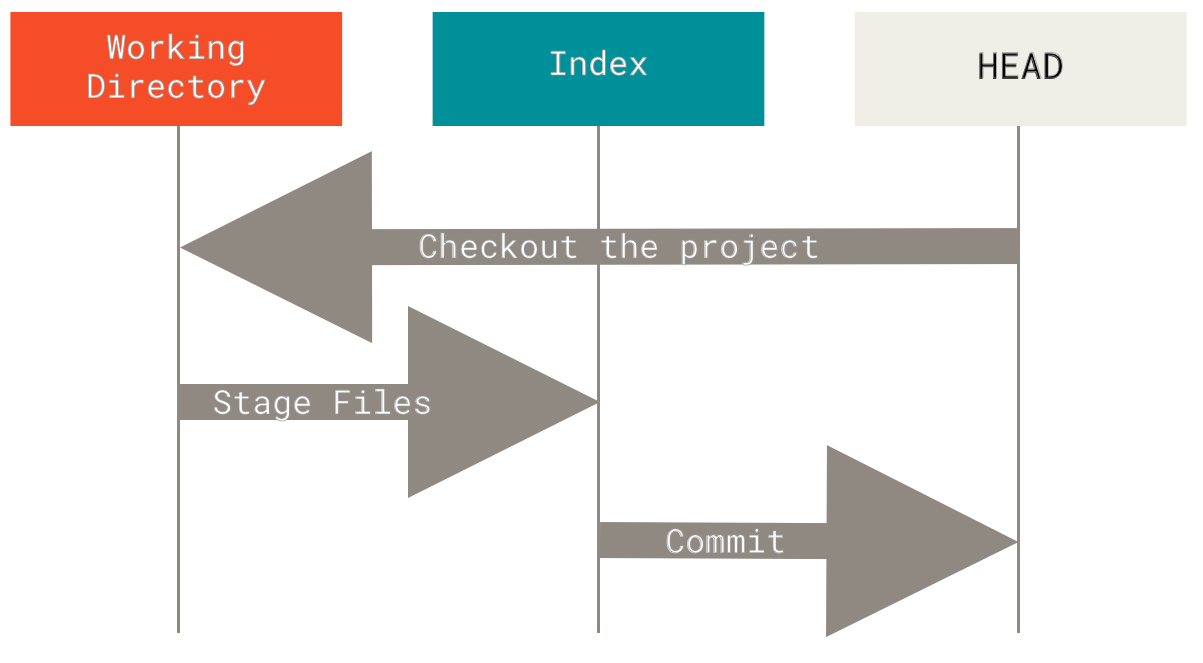
让我们可视化这个过程:假设你进入一个新目录,里面只有一个文件。我们称之为文件的 **v1** 版本,并用蓝色表示。现在我们运行 git init,它会创建一个 Git 仓库,并有一个指向未出生 master 分支的 HEAD 引用。
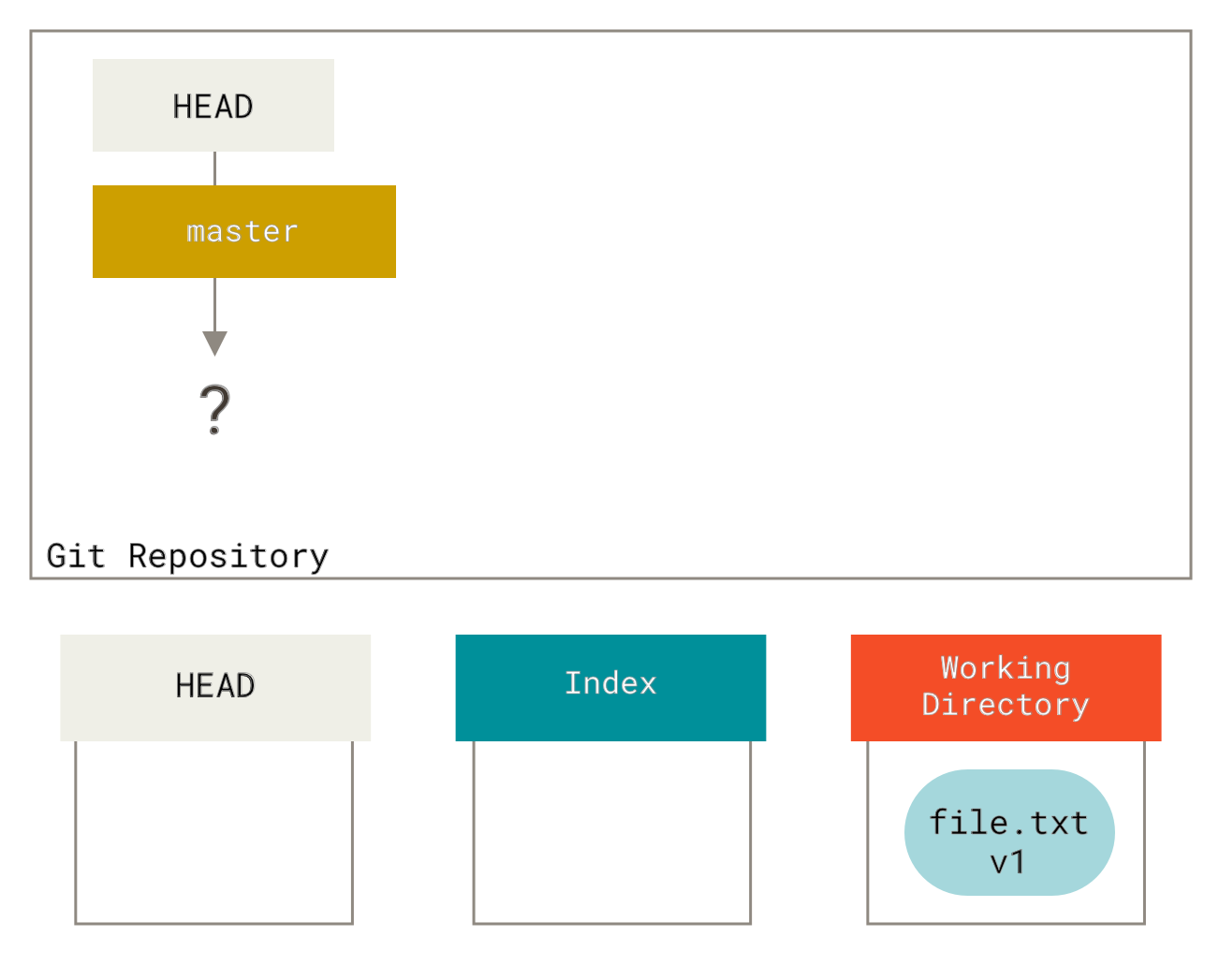
此时,只有工作目录树包含内容。
现在我们想提交这个文件,所以我们使用 git add 将工作目录中的内容复制到索引。
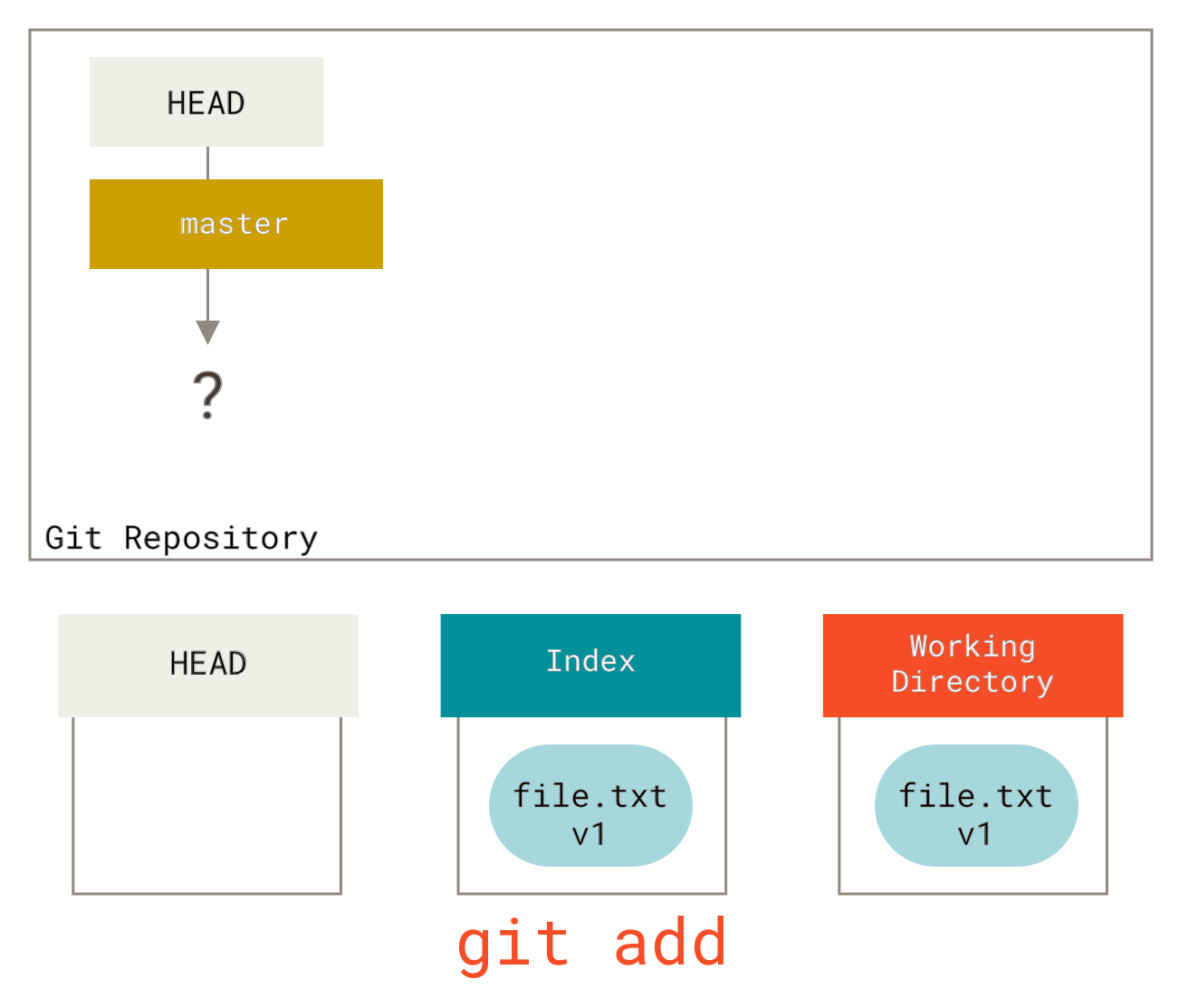
git add 操作将文件复制到索引然后我们运行 git commit,它会将索引的内容保存为一个永久的快照,创建一个指向该快照的提交对象,并更新 master 指针指向该提交。
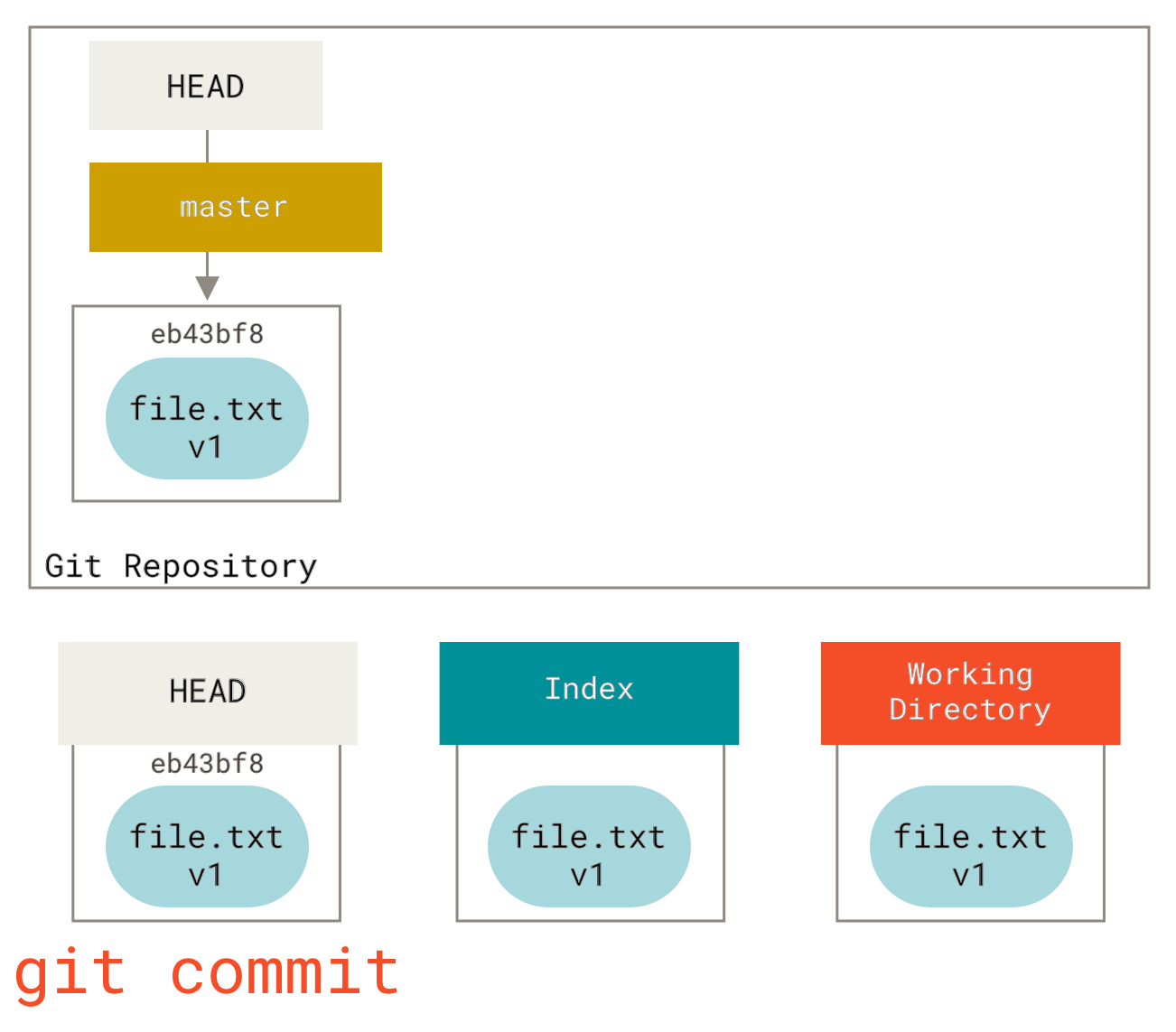
git commit 步骤如果我们运行 git status,会看到没有变化,因为所有三棵树都是相同的。
现在我们想修改这个文件并提交它。我们将遵循相同的过程;首先,我们在工作目录中修改文件。我们称之为文件的 **v2** 版本,并用红色表示。
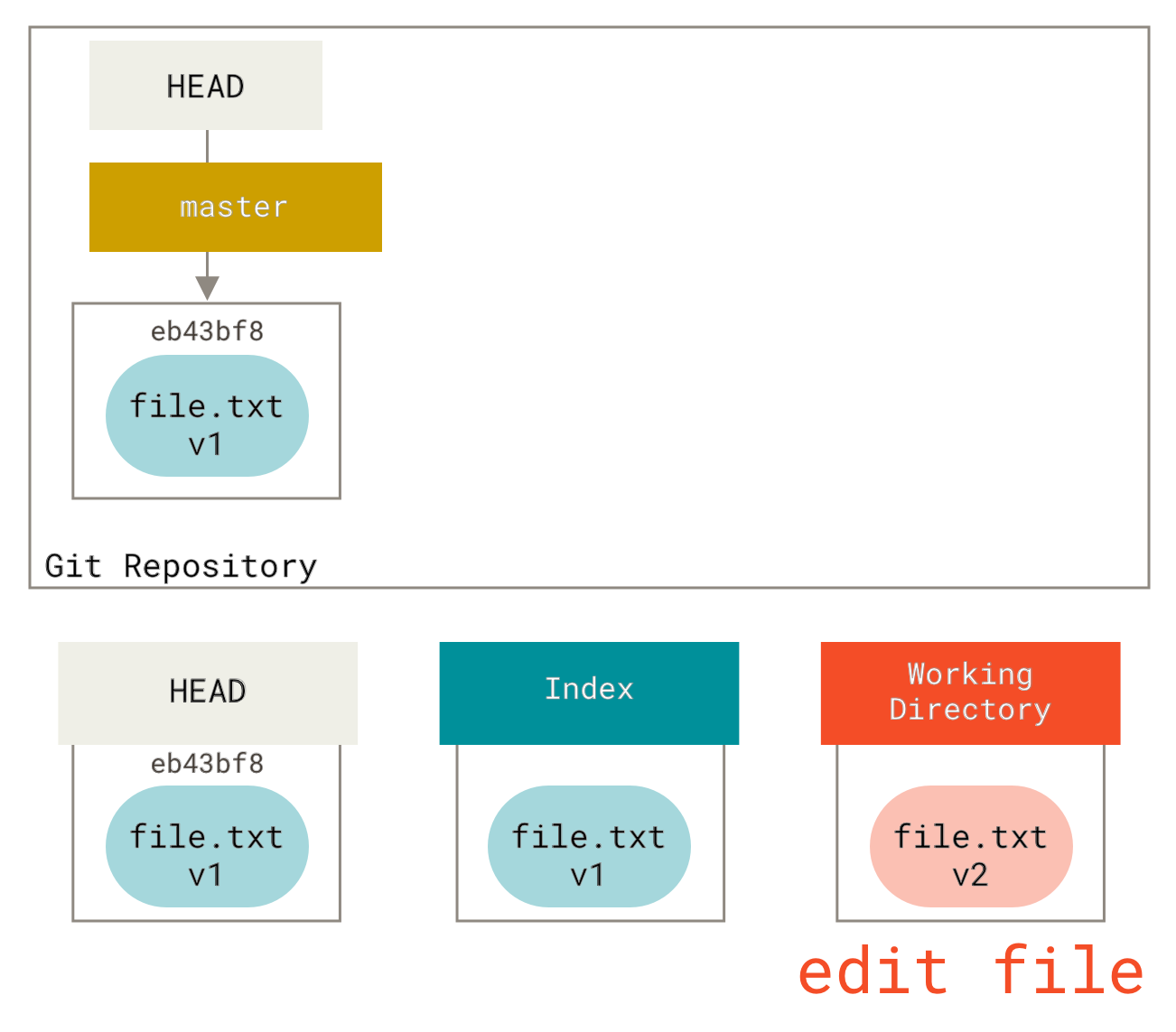
如果我们现在运行 git status,会看到该文件是红色的,显示为“Changes not staged for commit”(未暂存的更改),因为索引和工作目录中的条目不同。接下来,我们对其运行 git add 将其暂存到索引。
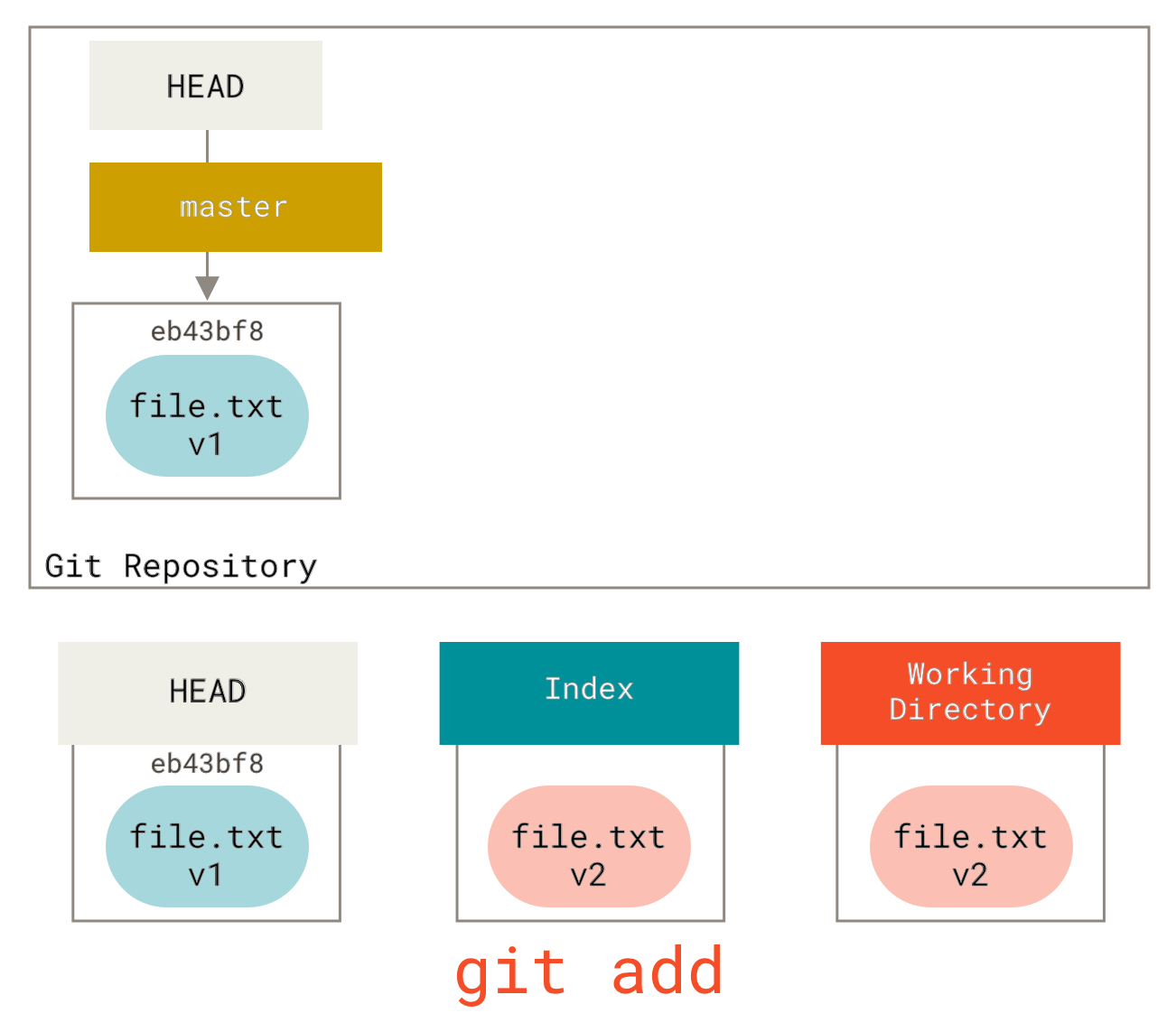
此时,如果我们运行 git status,会在“Changes to be committed”(待提交的更改)下看到该文件是绿色的,因为索引和 HEAD 不同——也就是说,我们提议的下一次提交现在与上次提交不同了。最后,我们运行 git commit 来完成提交。
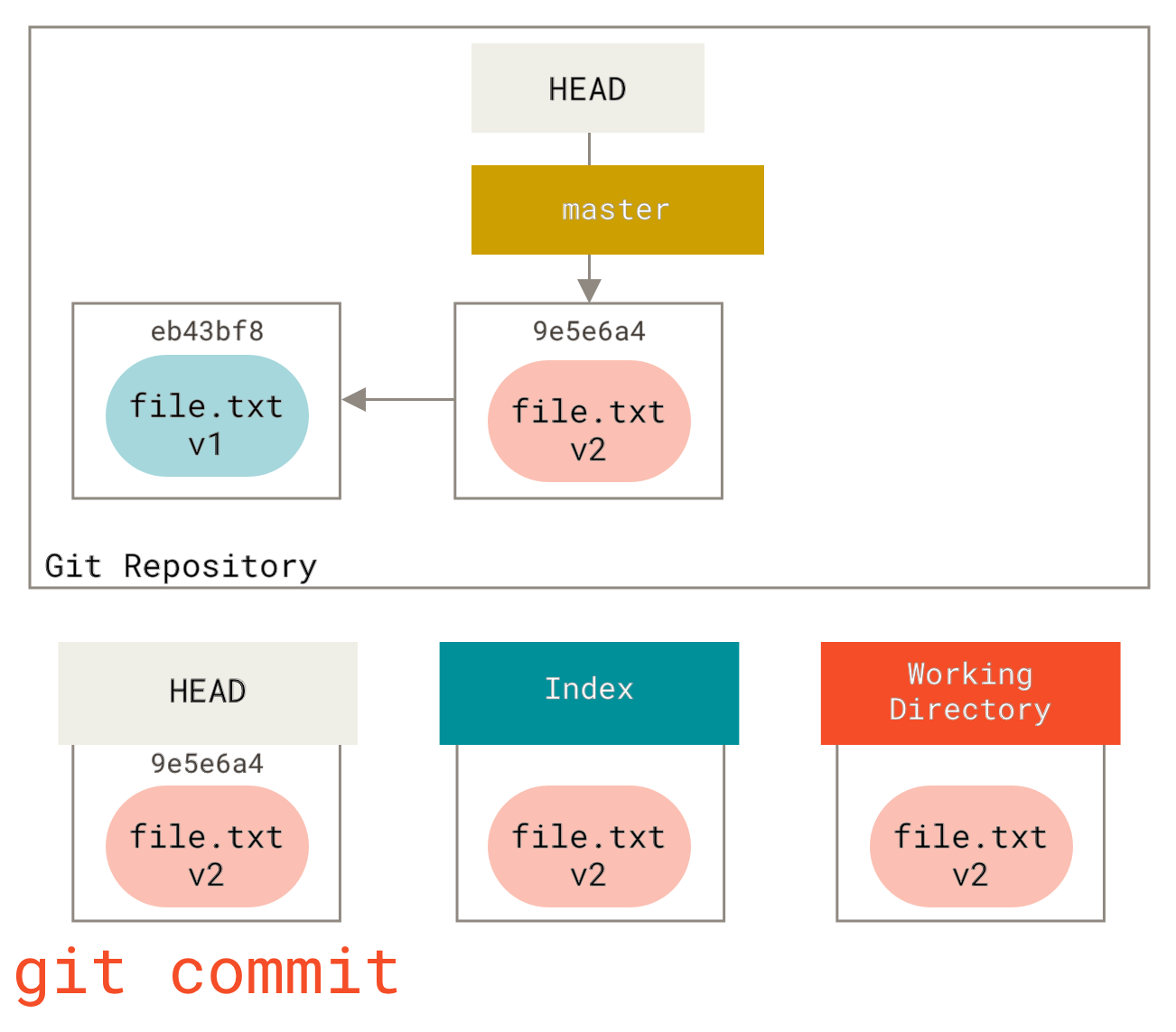
git commit 步骤现在 git status 将不会有任何输出,因为所有三棵树再次相同。
切换分支或克隆也遵循类似的过程。当你检出一个分支时,它会更新 **HEAD** 指向新的分支引用,用该提交的快照填充你的 **索引**,然后将 **索引** 的内容复制到你的 **工作目录**。
Reset 的作用
在此背景下,reset 命令会变得更容易理解。
为了演示的方便,我们假设我们再次修改了 file.txt 并进行了第三次提交。现在我们的历史看起来是这样的:
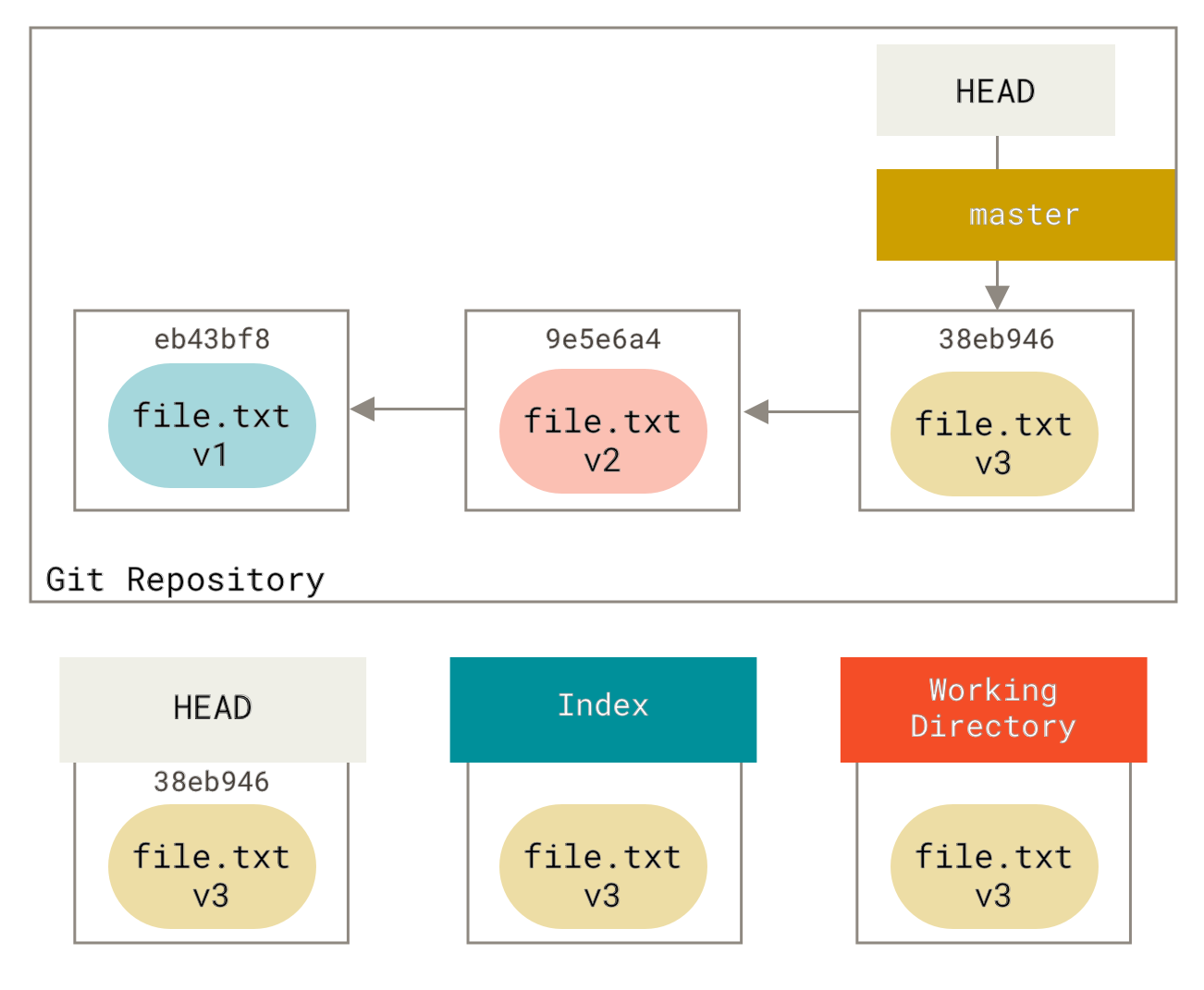
现在让我们一步步分析 reset 调用时确切的操作。它以一种简单且可预测的方式直接操作这三棵树。它最多执行三个基本操作。
步骤 1: 移动 HEAD
reset 首先会做的第一件事是移动 HEAD 所指向的对象。这与改变 HEAD 本身(checkout 所做的事情)不同;reset 移动的是 HEAD 所指向的分支。这意味着如果 HEAD 指向 master 分支(例如,你当前在 master 分支),运行 git reset 9e5e6a4 将首先使 master 指向 9e5e6a4。
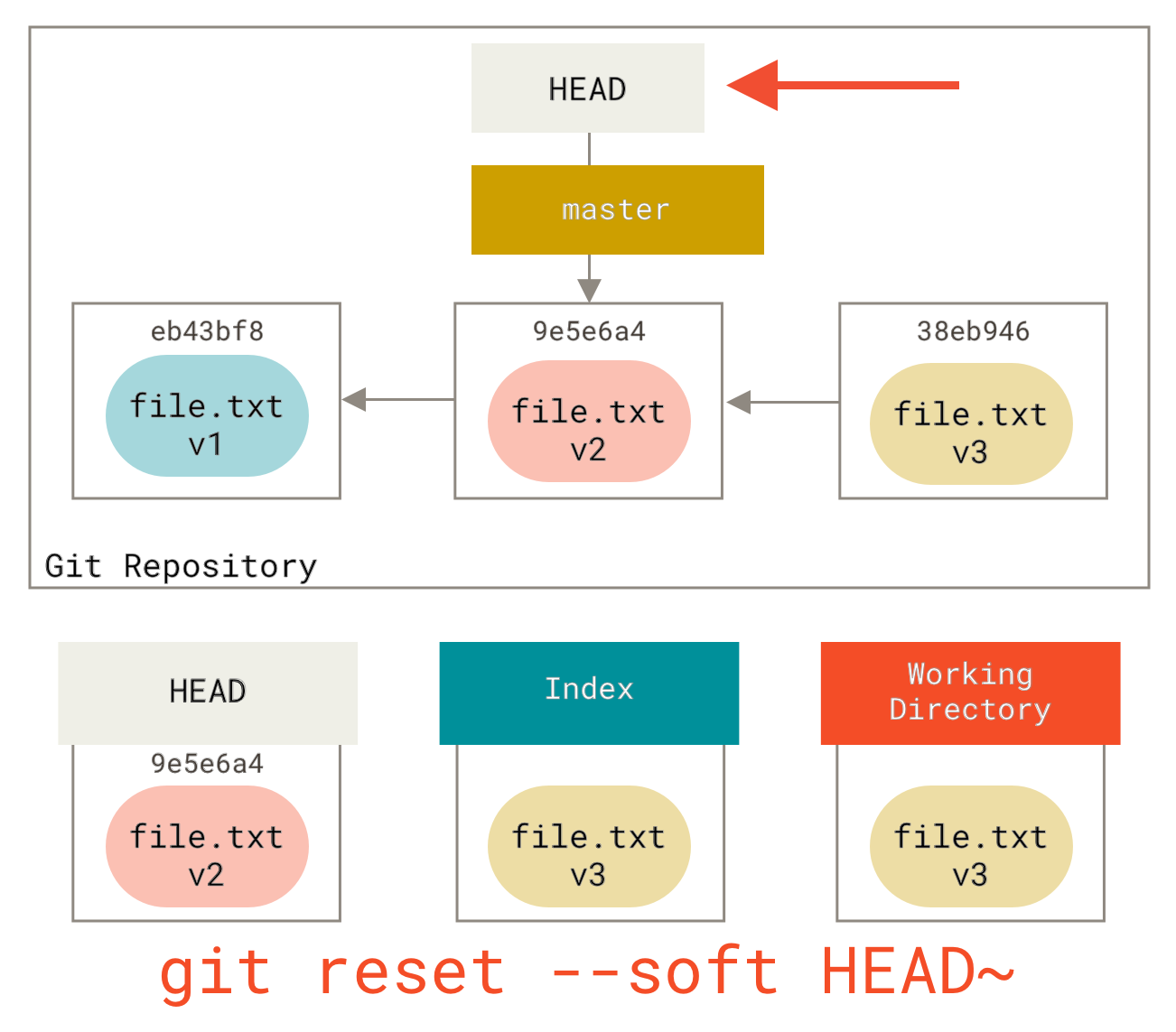
无论你调用哪种形式的带提交的 reset,它总是会先尝试这个操作。对于 reset --soft,它会在此停止。
现在花点时间看看这个图,理解发生了什么:它基本上撤销了最后一次 git commit 命令。当你运行 git commit 时,Git 创建一个新的提交并将 HEAD 指向的分支向上移动到这个新提交。当你 reset 回到 HEAD~(HEAD 的父提交)时,你将分支移回到原来的位置,而不改变索引或工作目录。之后,你可以更新索引并再次运行 git commit 来完成 git commit --amend 所能做的事情(参见修改最后一次提交)。
步骤 2: 更新索引 (--mixed)
注意,如果你现在运行 git status,你会看到索引和新的 HEAD 之间的差异(以绿色显示)。
reset 接下来要做的是用 HEAD 现在指向的快照的内容来更新索引。
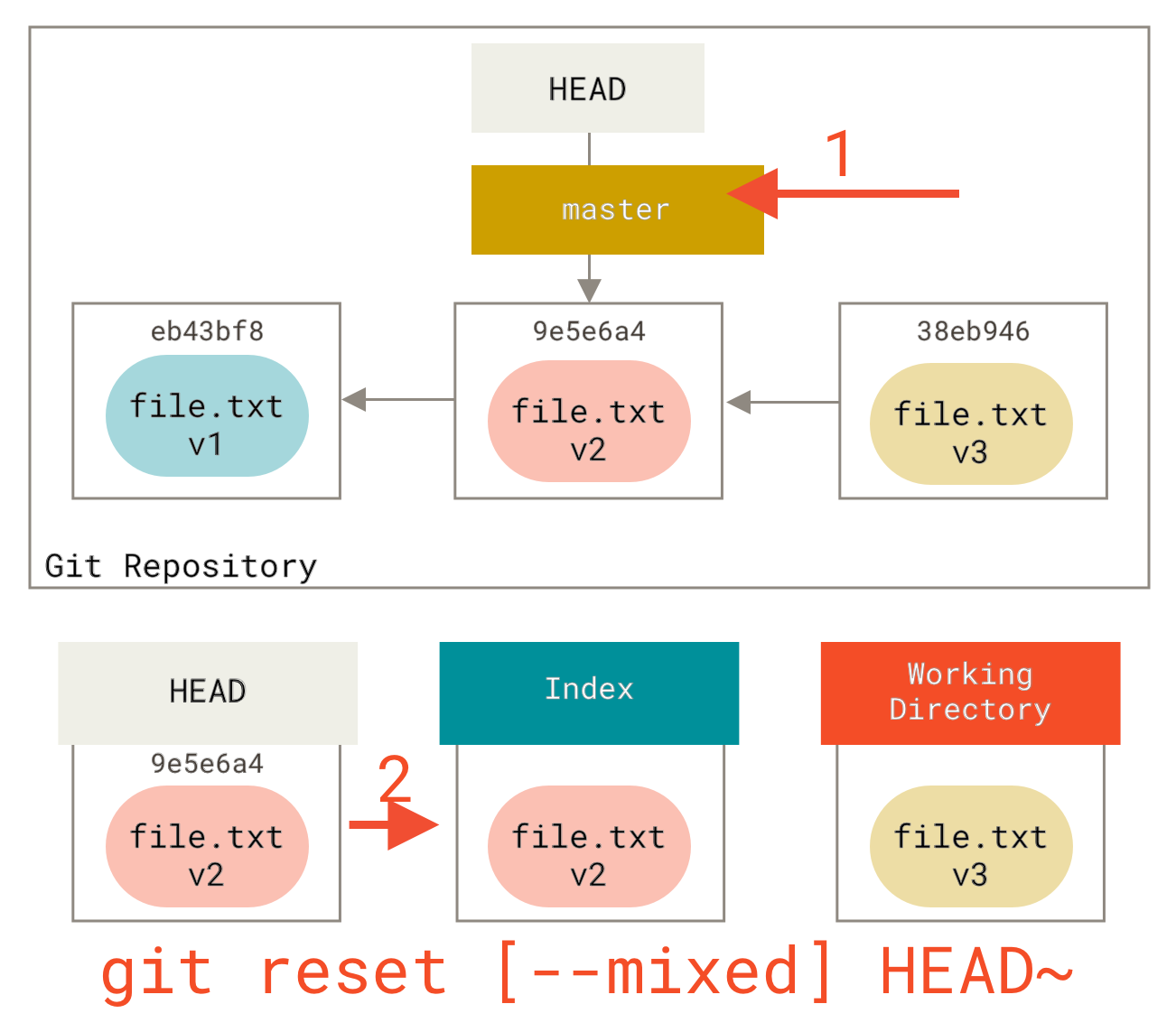
如果你指定了 --mixed 选项,reset 将在此停止。这也是默认选项,所以如果你根本不指定任何选项(在本例中就是 git reset HEAD~),命令就会在此停止。
再花点时间看看这个图,理解发生了什么:它仍然撤销了你最后一次 commit,而且还取消了所有暂存。你回滚到了运行所有 git add 和 git commit 命令之前的状态。
步骤 3: 更新工作目录 (--hard)
reset 要做的第三件事是使工作目录看起来像索引。如果你使用了 --hard 选项,它将继续进行到这一步。
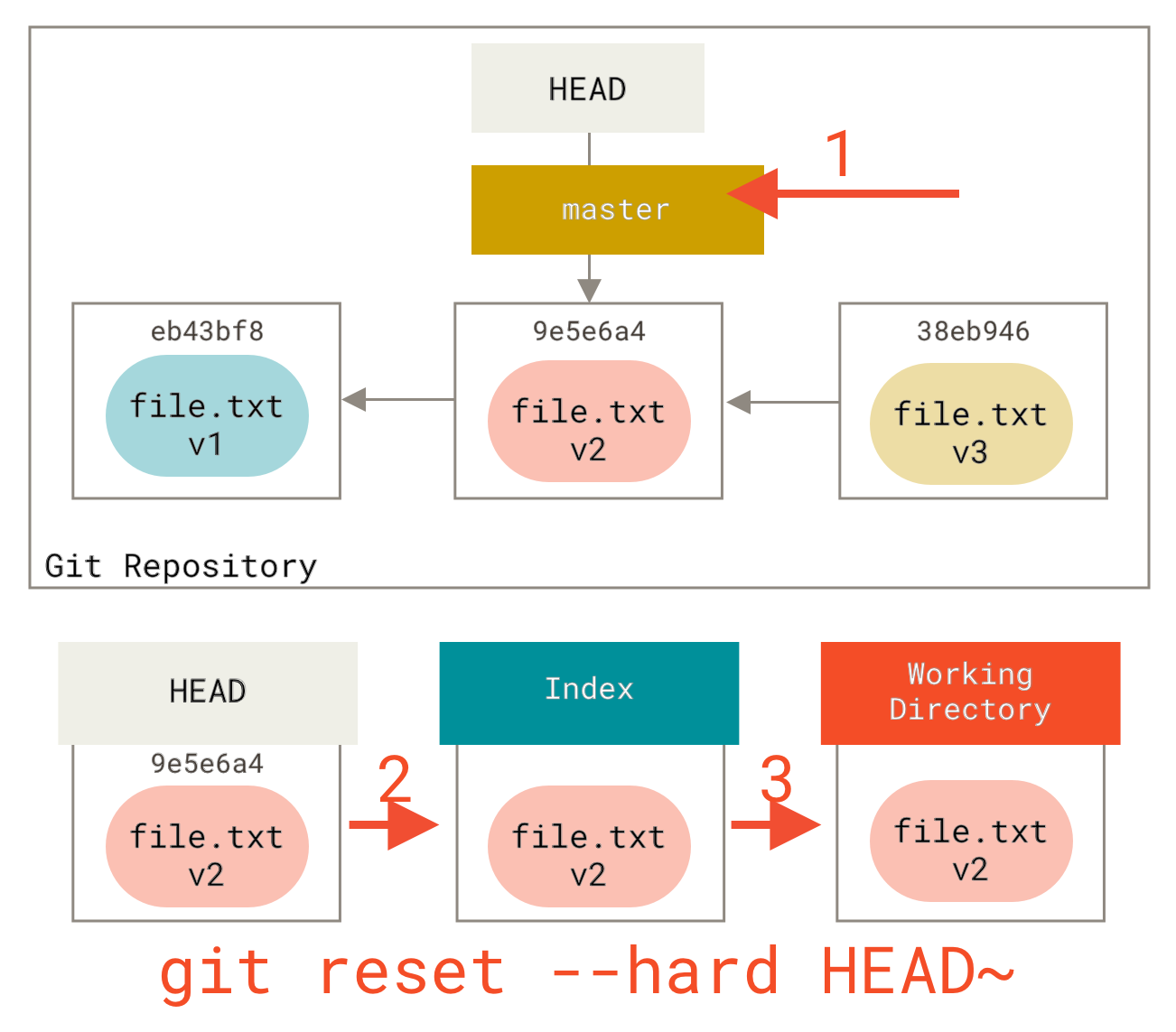
所以,让我们想想刚才发生了什么。你撤销了最后一次提交,git add 和 git commit 命令,以及你在工作目录中完成的所有工作。
需要注意的是,这个标志(--hard)是使 reset 命令危险的唯一方式,也是 Git 真正销毁数据的极少数情况之一。其他任何形式的 reset 调用都可以很容易地撤销,但 --hard 选项不行,因为它会强制覆盖工作目录中的文件。在这种特定情况下,我们的文件 **v3** 版本仍然在 Git 数据库的一个提交中,我们可以通过查看 reflog 来找回它,但如果我们还没有提交它,Git 仍然会覆盖文件,而且将无法恢复。
回顾
reset 命令会按照特定顺序覆盖这三棵树,并在你告诉它停止的地方停止。
-
移动 HEAD 指向的分支*(如果使用
--soft则在此停止)*。 -
使索引看起来像 HEAD*(除非使用
--hard否则在此停止)*。 -
使工作目录看起来像索引。
带路径的 Reset
以上涵盖了 reset 的基本行为,但你也可以提供一个路径来对其进行操作。如果你指定了一个路径,reset 将跳过步骤 1,并将剩余操作限制在特定的文件或一组文件上。这实际上是有道理的——HEAD 只是一个指针,你不能同时指向一个提交的一部分和另一个提交的一部分。但是索引和工作目录可以被部分更新,所以 reset 会继续执行步骤 2 和 3。
所以,假设我们运行 git reset file.txt。这种形式(因为你没有指定提交 SHA-1 或分支,也没有指定 --soft 或 --hard)是 git reset --mixed HEAD file.txt 的简写,它将:
-
移动 HEAD 指向的分支*(已跳过)*。
-
使索引看起来像 HEAD*(在此停止)*。
所以它基本上只是将 HEAD 中的 file.txt 复制到索引。
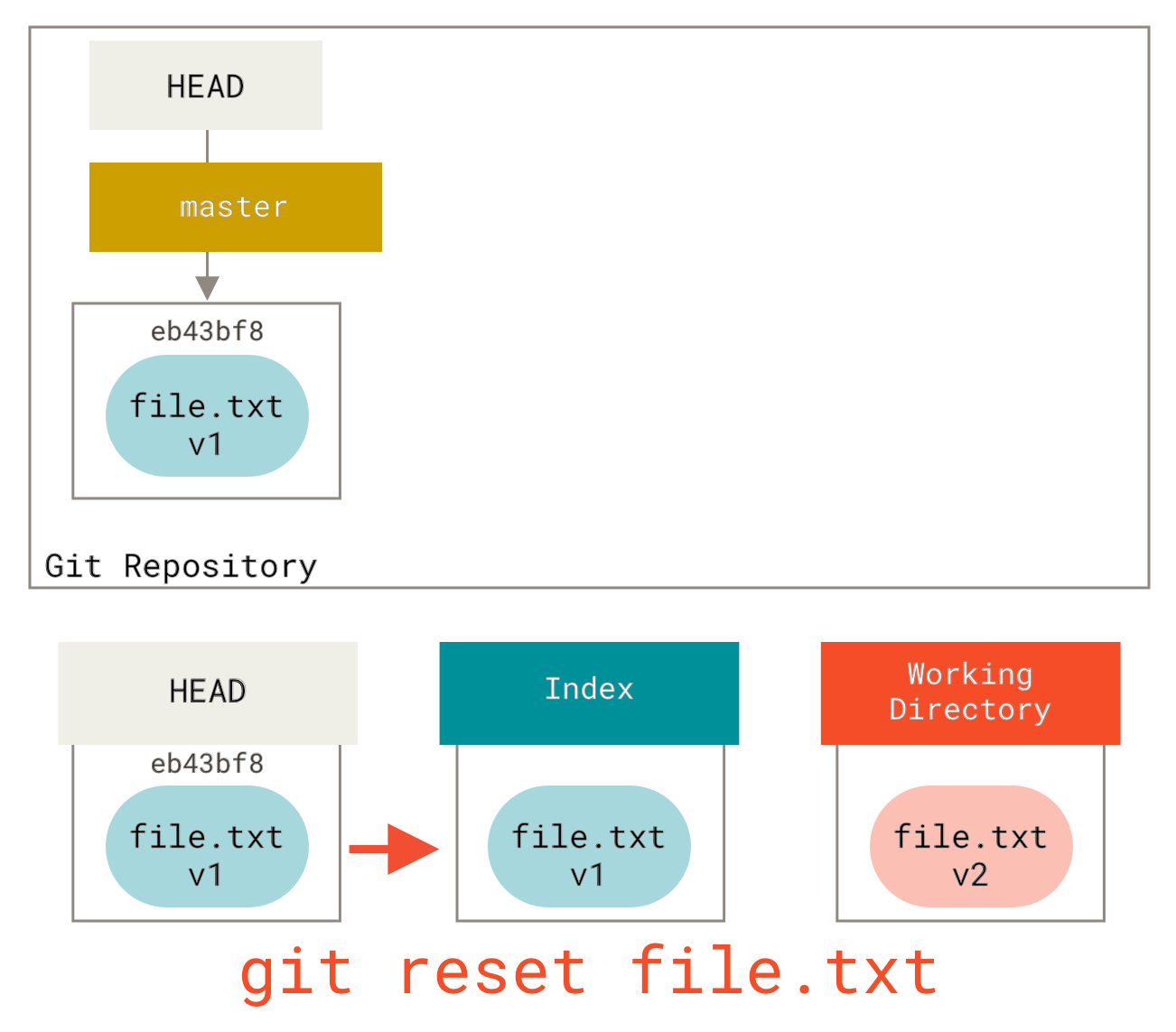
这实际上起到了取消暂存文件的作用。如果我们看看该命令的图,并思考 git add 的作用,它们是完全相反的。
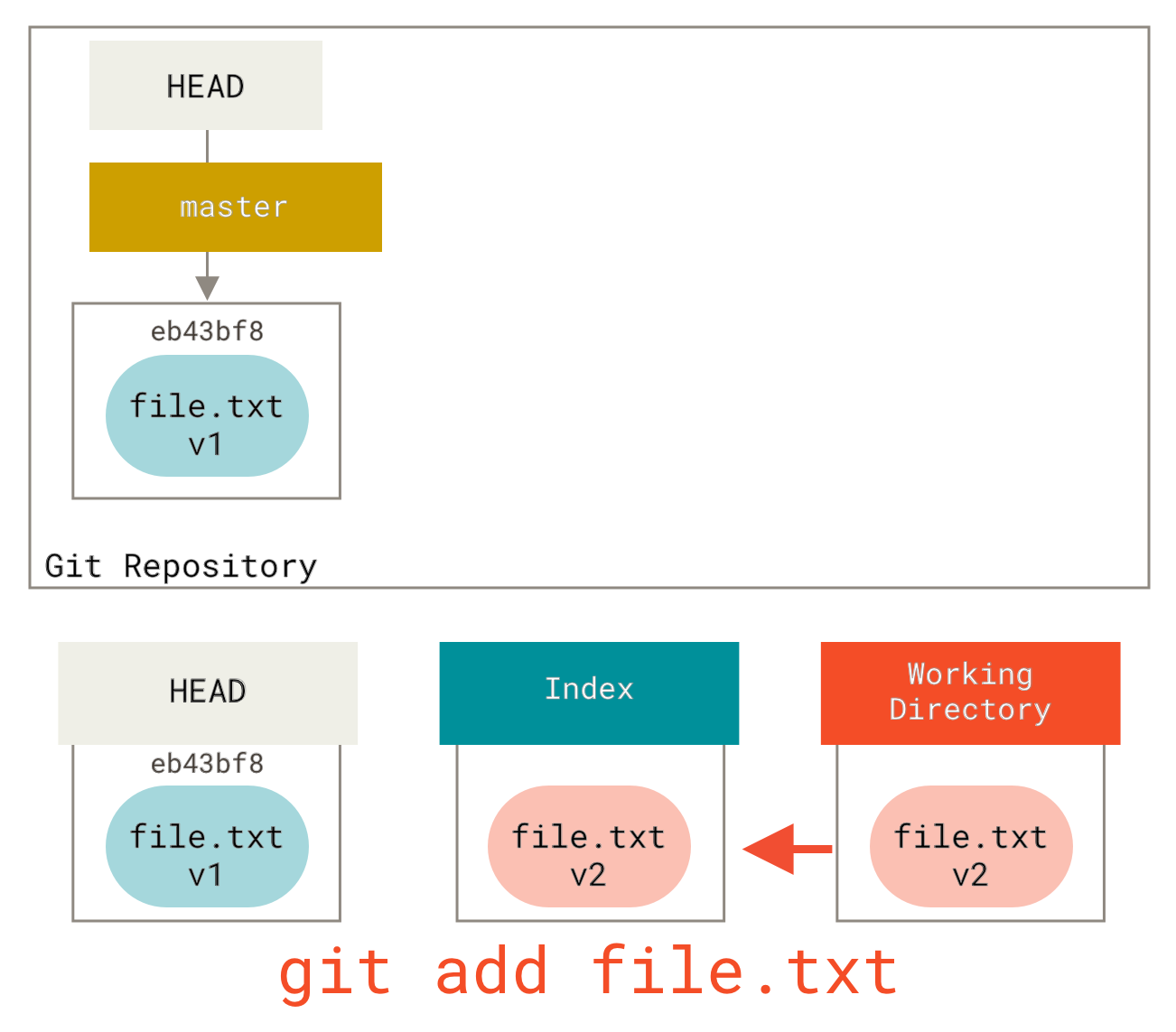
这就是为什么 git status 命令的输出会建议你运行此命令来取消暂存文件(更多关于此内容请参见取消暂存已暂存的文件)。
我们也可以通过指定一个特定的提交来让 Git 不再假定我们指的是“从 HEAD 拉取数据”,而是从那个提交中拉取文件版本。我们可以运行类似 git reset eb43bf file.txt 的命令。
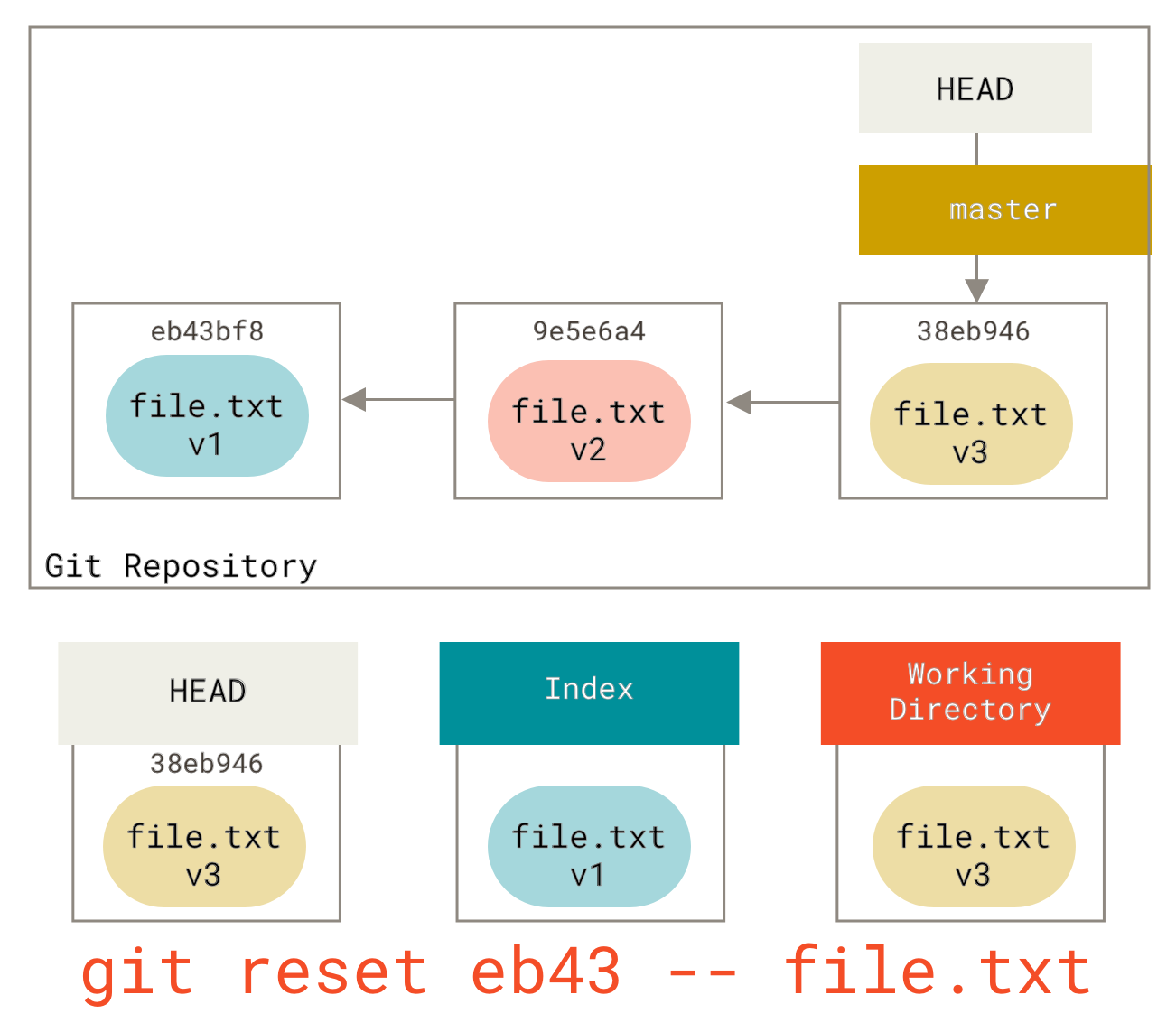
这实际上与我们之前将文件的内容还原到工作目录中的 **v1**,然后运行 git add,再将其还原到 **v3**(而无需实际执行所有这些步骤)的效果相同。如果我们现在运行 git commit,它将记录一个将该文件还原到 **v1** 的更改,即使我们实际上从未在工作目录中再次看到它。
还有一点也很有趣,与 git add 一样,reset 命令也接受 --patch 选项,允许你逐个 hunks 地取消暂存内容。因此,你可以选择性地取消暂存或还原内容。
合并提交 (Squashing)
让我们看看如何利用这个新发现的能力做一些有趣的事情——合并提交。
假设你有一系列提交,提交信息像是“oops.”、“WIP”和“forgot this file”。你可以使用 reset 将它们快速轻松地合并成一个让你看起来很聪明的提交。 合并提交展示了另一种方法,但在本例中,使用 reset 更简单。
假设你的项目中的第一次提交只有一个文件,第二次提交添加了一个新文件并修改了第一个文件,第三次提交再次修改了第一个文件。第二次提交是一个未完成的工作,你想把它合并掉。
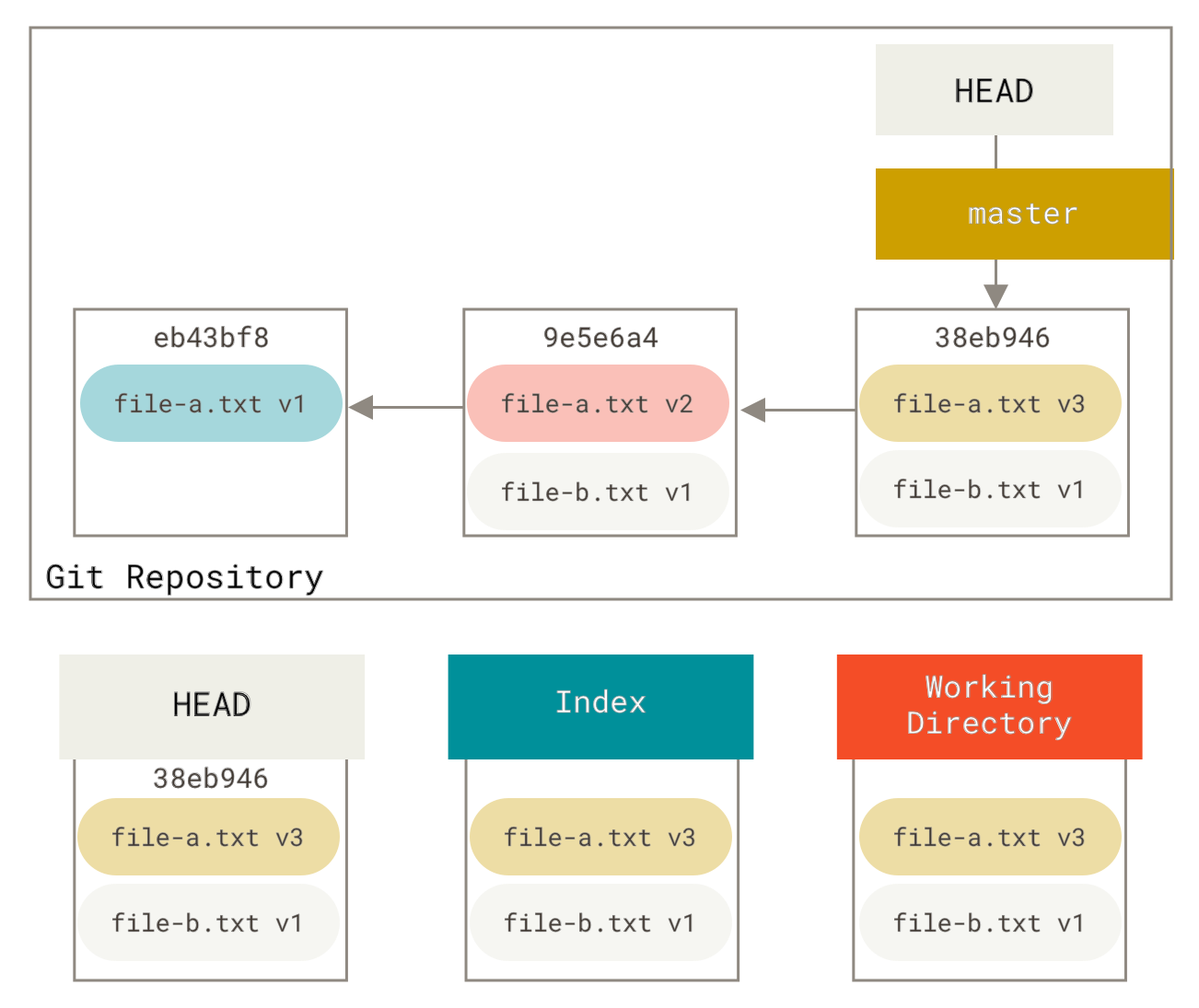
你可以运行 git reset --soft HEAD~2 将 HEAD 分支移回一个较旧的提交(你想保留的最新提交)
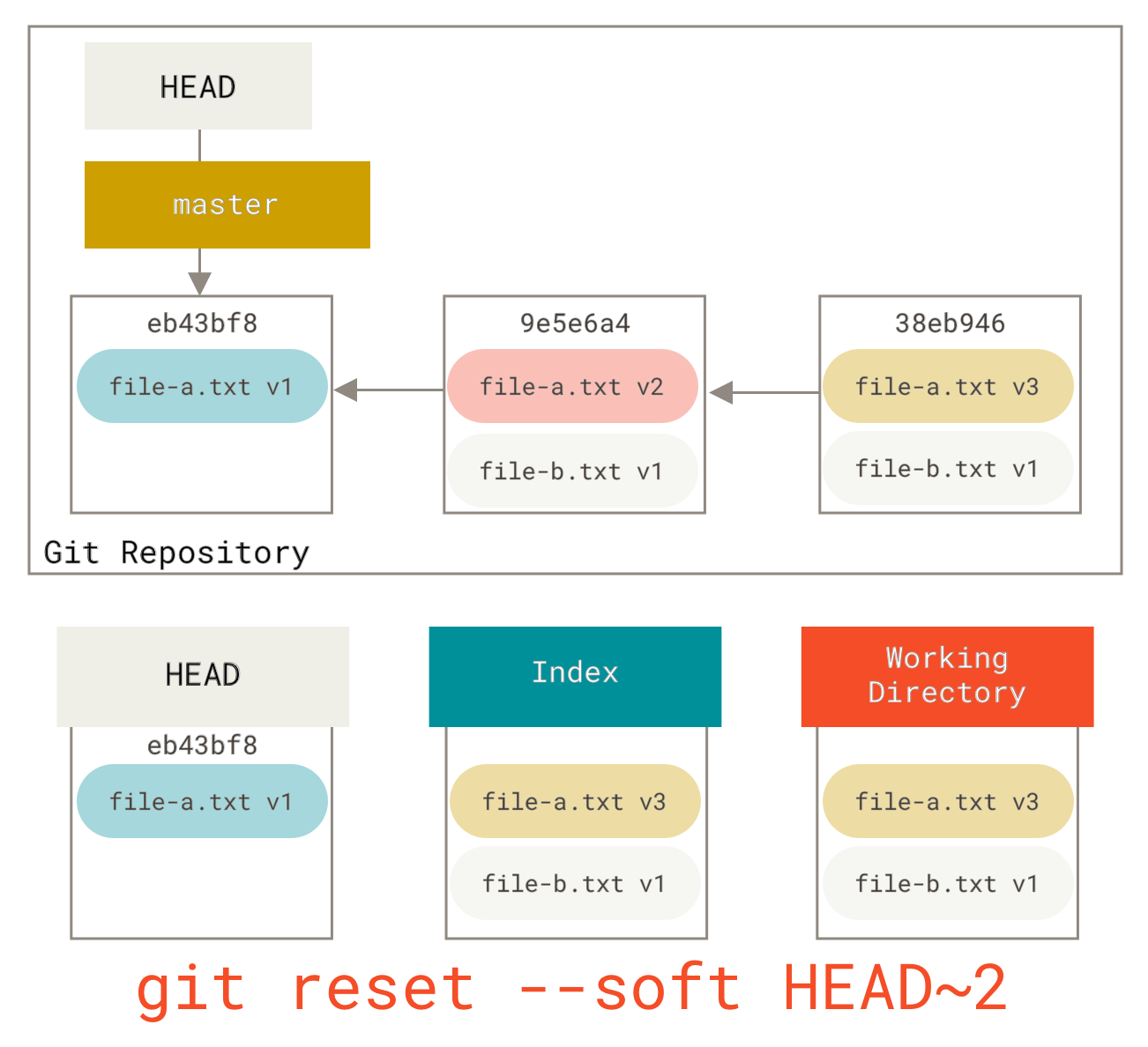
然后简单地再次运行 git commit
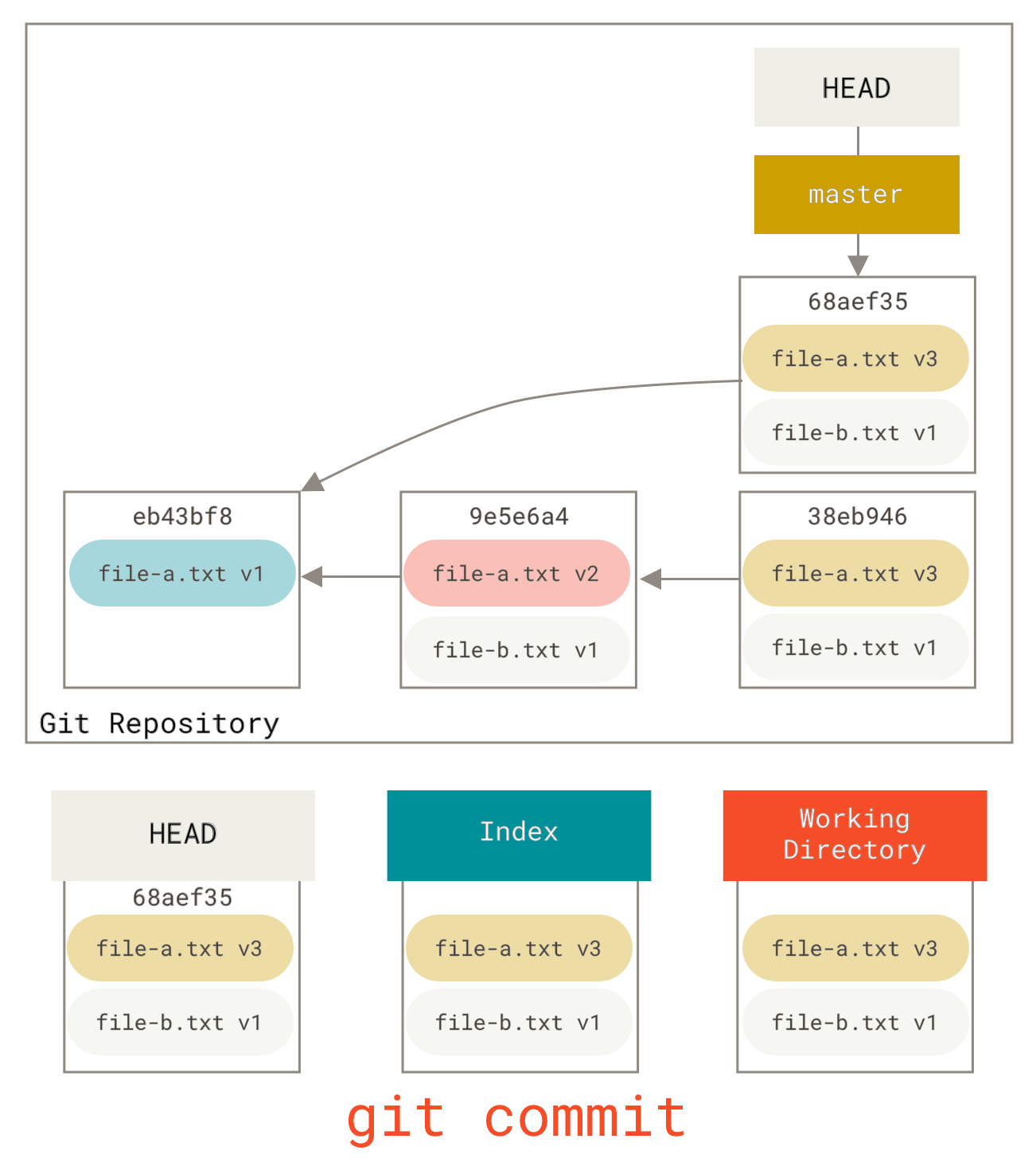
现在你可以看到,你的可达历史(也就是你将要推送的历史)看起来就像你有一个提交包含 file-a.txt **v1**,然后第二个提交同时将 file-a.txt 修改为 **v3** 并添加了 file-b.txt。包含文件 **v2** 版本的提交已不再历史记录中。
检出 (Check It Out)
最后,你可能想知道 checkout 和 reset 之间的区别。与 reset 类似,checkout 也操作这三棵树,并且根据你是否为命令提供文件路径,其行为略有不同。
没有路径时
运行 git checkout [branch] 在很多方面与运行 git reset --hard [branch] 相似,因为它会更新所有三棵树以匹配 [branch],但有两个重要区别。
首先,与 reset --hard 不同,checkout 对工作目录是安全的;它会检查以确保不会覆盖有更改的文件。实际上,它更智能一些——它会尝试在工作目录中进行简单的合并,因此所有你*没有*更改的文件都会被更新。而 reset --hard 会直接替换所有文件,不做任何检查。
第二个重要区别是 checkout 如何更新 HEAD。reset 会移动 HEAD 所指向的分支,而 checkout 会移动 HEAD 本身来指向另一个分支。
例如,假设我们有 master 和 develop 分支,它们指向不同的提交,并且我们当前在 develop 分支(所以 HEAD 指向它)。如果我们运行 git reset master,develop 本身将指向与 master 相同的提交。如果我们运行 git checkout master,develop 不会移动,移动的是 HEAD 本身。HEAD 现在将指向 master。
因此,在这两种情况下,我们都是将 HEAD 指向提交 A,但*方式*却大不相同。reset 会移动 HEAD 所指向的分支,checkout 移动 HEAD 本身。
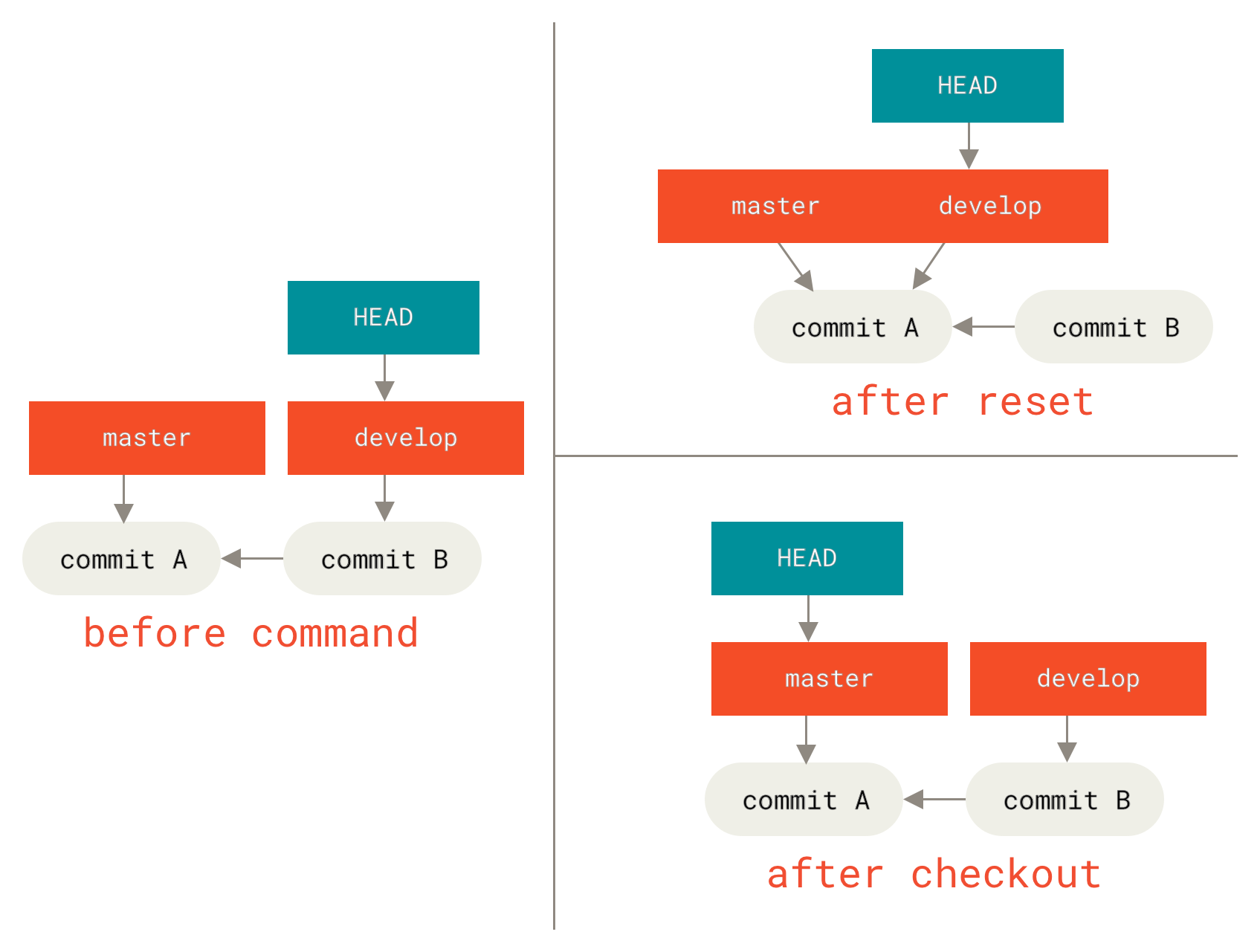
git checkout 和 git reset带路径时
checkout 的另一种用法是带上文件路径,这与 reset 一样,不会移动 HEAD。它就像 git reset [branch] file 一样,它会用那个提交中的文件更新索引,但它也会覆盖工作目录中的文件。它就像 git reset --hard [branch] file 一样(如果 reset 允许你那样运行的话)——它对工作目录不安全,并且不移动 HEAD。
同样,与 git reset 和 git add 一样,checkout 也接受 --patch 选项,允许你逐个 hunks 地选择性地还原文件内容。
总结
希望现在你对 reset 命令有了更好的理解和信心,但可能仍然对它与 checkout 的确切区别感到困惑,并且不可能记住所有不同调用的规则。
这里有一个备忘单,说明哪些命令会影响哪些树。“HEAD”列如果命令移动 HEAD 所指向的引用(分支),则显示“REF”,如果命令移动 HEAD 本身,则显示“HEAD”。请特别注意“WD Safe?”(工作目录安全?)列——如果显示为 **NO**,请在运行该命令前三思。
| HEAD | 索引 (Index) | 工作目录 | WD Safe? | |
|---|---|---|---|---|
提交级别 |
||||
|
REF |
NO |
NO |
YES |
|
REF |
YES |
NO |
YES |
|
REF |
YES |
YES |
NO |
|
HEAD |
YES |
YES |
YES |
文件级别 |
||||
|
NO |
YES |
NO |
YES |
|
NO |
YES |
YES |
NO |